

Deployment + Maintenance
Deploy open-source applications instantly on your cloud
- Simple Instant Deployment Instantly deploy in your company’s cloud on.
- Robust Security Continuous security scans to ensure your deployment is safe.
- Control Dashboard Easily manage your open-source applications.

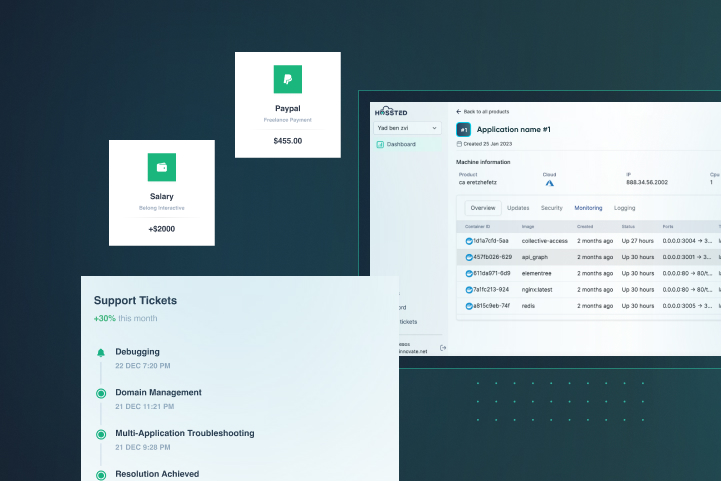
Support
Support all of your open-source applications with one SLA
- 30 Minute Response Time Our support team will reach out to you within 30 minutes of you contacting our team.
- Support Any Time You Need It (24/7) Regardless of your time zone or location, our team of dedicated support professionals can always assist you.
- Quick Resolution Guaranteed On average our team of experts will be able to solve any problem you have ithin 48 hours.
Features
- In-memory data grid
- Distributed caching
- Scalability
- High availability

Check other related applications
